

- Published on
Reverse-Engineering of Website Network Requests
- Authors
- Name
- Nathan Brake
- @njbrake



We may now take it for granted, but browsing the web is magic: you enter URLs into the address bar in your browser, and you're brought to sites that contain all sorts of text, image and video. curl is a command line utility that can be used to make HTTP requests. Using Chrome developer tools, we can mimic the request that a browser makes in order to receive the exact same data. Although tools like Selenium allow for automation of browser functionality, it can be complex and computationally expensive to run automated tasks, since selenium opens and runs a browser to perform the automation. Using curl we can send only the minimum necessary HTTP requests required to accomplish our task.
I recently used this method to help automate a process at work, but for this example I'll show how to quickly use chrome and curl to make a simple search request to google. With the resulting html page we could then use BeautifulSoup to parse the html and extract the search results. I won't go into that part here, but maybe I'll cover it in a future post.
Chrome Devtools record network traffic
I use built-in functionality of the Chrome web browser to record the network traffic; similar functionality exists in other browsers like Safari and Edge.
The Chrome developers have a well written tutorial on how to use their devtools here.
What doesn't work
Making a google search request is as simple as entering https://www.google.com/search?q=3M into your browser window. You may be tempted to open a bash terminal and use curl to make a search request to google with a similar command:
curl https://www.google.com/search?q=3M -o google.html
However, if you open this produced google.html page, you'll see that it gives you an error page that looks like this instead:

The reason this fails isn't because curl can't make the search request, but because when you make a HTTP request inside the browser, the browser is attaching lots of other types of information to the GET request (headers and cookies) that aren't easily visible. We can use the Chrome devTools to figure out exactly what that data is!
Extracting a curl request from Chrome Devtools
As explained in the Chrome devtools tutorial, the devtools network tab (devtools opened by pressing F12) will record all the network traffic that occurs when you load a page. In order to record the request that happens when we make the google search request, we need to clear the network log, then make the request. The first request that appears in the network tab will be the one we want to examine and copy. By manually inspecting the request, you can see that Chrome is attaching a whole lot of information with the request via something called "headers". Headers are a way of sending metadata along with the request. In this case, the headers are telling google that we are using Chrome, and that we are using a certain version of Chrome, and that we are using a certain operating system, etc.
As shown in the screenshot below, we can directly copy the request as a curl command by right clicking on the request and selecting "Copy > Copy as curl".
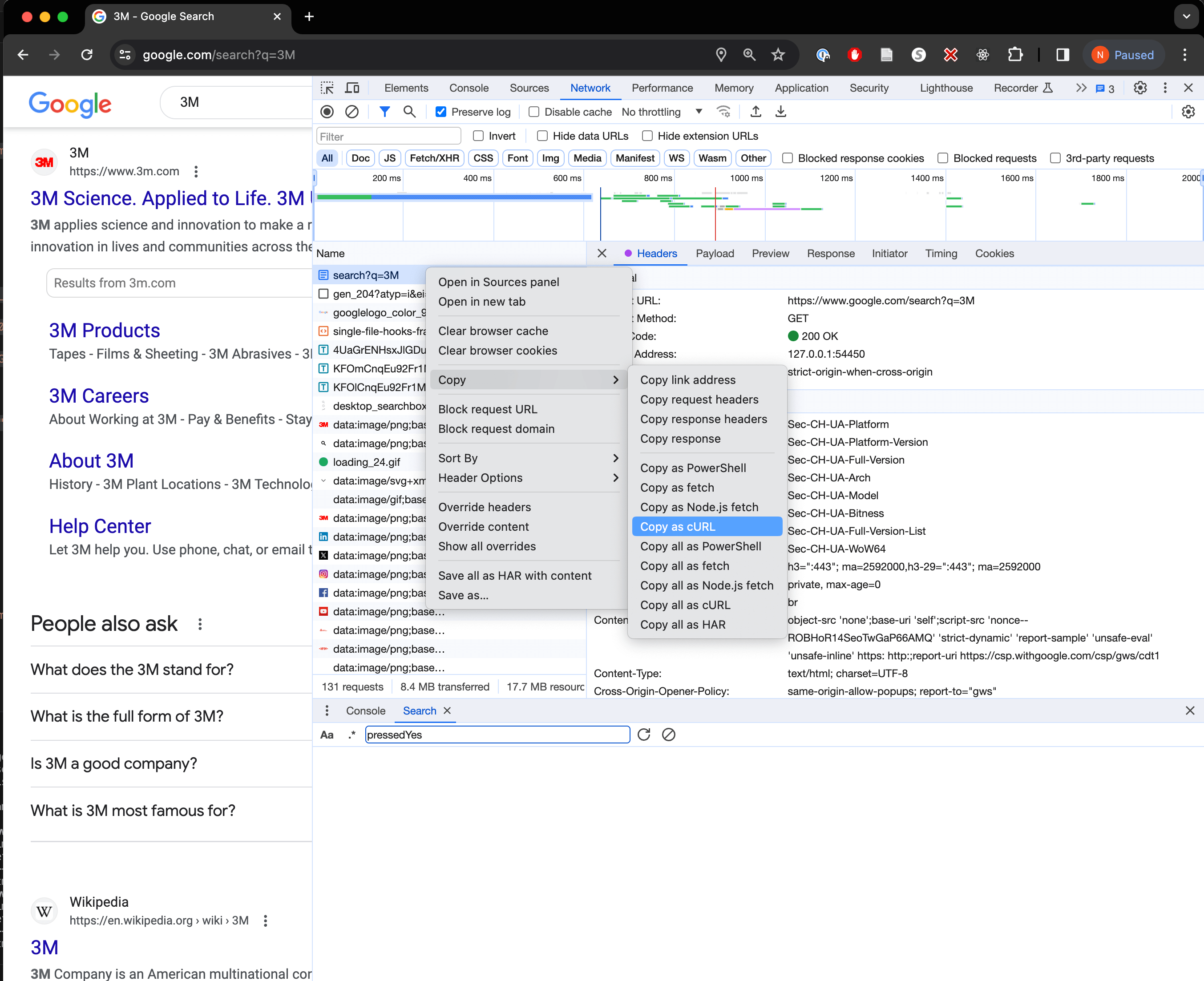
The command we copied looks like this:
curl 'https://www.google.com/search?q=3M' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \
-H 'Accept-Language: en-US,en;q=0.9' \
-H 'Cache-Control: max-age=0' \
-H 'Connection: keep-alive' \
-H 'Sec-Fetch-Dest: document' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-Site: none' \
-H 'Sec-Fetch-User: ?1' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' \
-H 'X-Client-Data: CIW2yQEIorbJAQipncoBCJLgygEIlKHLAQiGoM0BCNy9zQEIucjNAQiP4c0BCN/rzQEI4uzNAQjh7c0BCIzvzQEIg/DNARjAy8wBGKfqzQEY642lFw==' \
-H 'sec-ch-ua: "Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"' \
-H 'sec-ch-ua-arch: "arm"' \
-H 'sec-ch-ua-bitness: "64"' \
-H 'sec-ch-ua-full-version: "120.0.6099.129"' \
-H 'sec-ch-ua-full-version-list: "Not_A Brand";v="8.0.0.0", "Chromium";v="120.0.6099.129", "Google Chrome";v="120.0.6099.129"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-model: ""' \
-H 'sec-ch-ua-platform: "macOS"' \
-H 'sec-ch-ua-platform-version: "14.2.1"' \
-H 'sec-ch-ua-wow64: ?0' \
-o google.html \
-D google_headers.txt \
--compressed
So this explains why our simple curl request didn't work, we need to add these headers to our request in order to get the same response that we would get from the browser. When the above command is run, now we get a reasonable result when we open the google.html file:
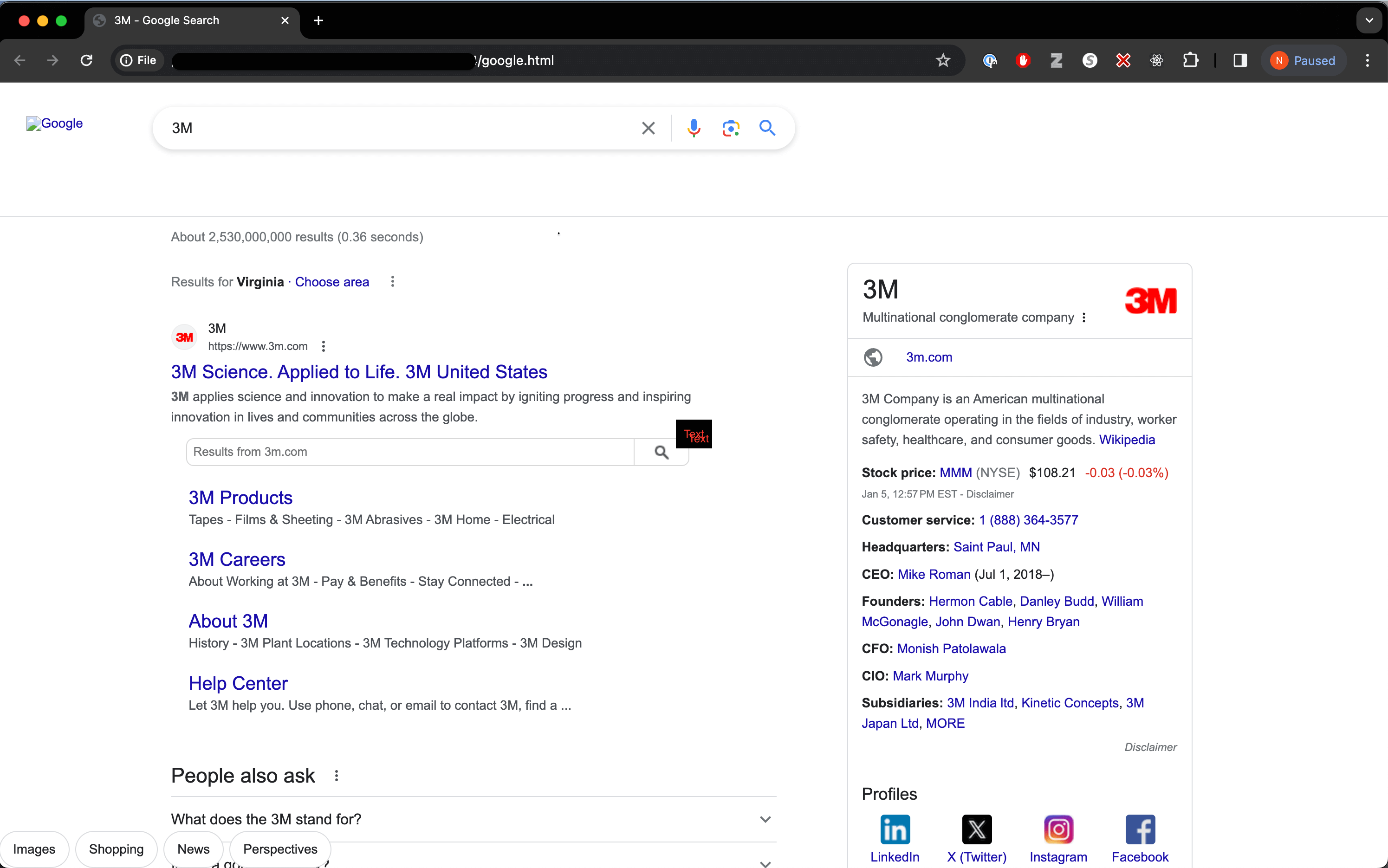
It's also worth looking at the google_headers.txt output file to see what headers google is sending back to us:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Date: Fri, 05 Jan 2024 18:19:56 GMT
Expires: -1
Cache-Control: private, max-age=0
Strict-Transport-Security: max-age=31536000
Content-Security-Policy: object-src 'none';base-uri 'self';script-src 'nonce-redacted' 'strict-dynamic' 'report-sample' 'unsafe-eval' 'unsafe-inline' https: http:;report-uri https://csp.withgoogle.com/csp/gws/cdt1
Cross-Origin-Opener-Policy: same-origin-allow-popups; report-to="gws"
Report-To: {"group":"gws","max_age":2592000,"endpoints":[{"url":"https://csp.withgoogle.com/csp/report-to/gws/cdt1"}]}
Accept-CH: Sec-CH-UA-Platform
Accept-CH: Sec-CH-UA-Platform-Version
Accept-CH: Sec-CH-UA-Full-Version
Accept-CH: Sec-CH-UA-Arch
Accept-CH: Sec-CH-UA-Model
Accept-CH: Sec-CH-UA-Bitness
Accept-CH: Sec-CH-UA-Full-Version-List
Accept-CH: Sec-CH-UA-WoW64
Permissions-Policy: unload=()
Origin-Trial: redacted
P3P: CP="This is not a P3P policy! See g.co/p3phelp for more info."
Content-Encoding: gzip
Server: gws
X-XSS-Protection: 0
X-Frame-Options: SAMEORIGIN
Set-Cookie: 1P_JAR=2024-01-05-18; expires=Sun, 04-Feb-2024 18:19:56 GMT; path=/; domain=.google.com; Secure; SameSite=none
Set-Cookie: AEC=redacted; expires=Wed, 03-Jul-2024 18:19:56 GMT; path=/; domain=.google.com; Secure; HttpOnly; SameSite=lax
Set-Cookie: NID=redacted; expires=Sat, 06-Jul-2024 18:19:56 GMT; path=/; domain=.google.com; Secure; HttpOnly; SameSite=none
Alt-Svc: h3=":443"; ma=2592000,h3-29=":443"; ma=2592000
Transfer-Encoding: chunked
From that headers.txt file we can see that google is sending back some cookies that the browser will use to identify us in future requests. Curl has a way to store cookies in a file so that we can use them in future requests. We can add the -c cookies.txt flag to the curl command to store the cookies in a file, and then add the -b cookies.txt flag to use the cookies in future requests.
Conclusion
Using the Chrome devtools to record network traffic, we can extract the exact HTTP request that the browser is making, and then use curl to make the same request. This allows us to automate tasks that would otherwise require a browser to be open and running. This method is also useful for debugging, since we can compare the request that our code is making to the request that the browser is making, and see if there are any differences.